Jeśli trochę już programowałeś, z pewnością słyszałeś o czymś takim jak undefined behavior – niezdefiniowane zachowanie. Jest to bardzo nieprzyjemna sytuacja, kiedy kompilator nie do końca wie, jak poprawnie się zachować. Wynika to głównie ze standardu, w którym niektóre operacje są opisane jako niezdefiniowane. Standard C99 definiuje prawie 200 takich sytuacji, Niezdefiniowane zachowanie może wynikać pośrednio także ze „sztuczek optymalizacyjnych” zastosowanych przez kompilator.
Warto wiedzieć nie tylko o sytuacjach najczęściej prowadzących do „undefined behavior”, ale także rozumieć co się dzieje po stronie kompilatora. Przeprowadzimy krótką analizę tej paskudnej cechy języka C/C++.
Z czego wynika undefined behavior?
Możesz zadać pytanie – po co w standardzie zostawiono jakieś niejasności? Dlaczego nie wyjaśniono dokładnie każdej możliwej sytuacji? Pozostawienie niektórych trudnych do rozpatrzenia niuansów „niezdefiniowanymi” pozwala znacznie uprościć budowę kompilatorów. (Te i tak ze względu na swoją naturę są bardzo skomplikowane). Innym powodem jest potrzeba zachowania kompatybilności z jak największą ilością architektur. różne architektury procesorów posiadają różne możliwości i różnie interpretują polecenia takie jak przesunięcie bitowe. Narzucenie z góry jakiegoś zachowania w konfliktowej sytuacji, takiej jak dzielenie przez zero mogłoby spowodować duży narzut na niektórych architekturach CPU. Ponadto, programy są szybsze. Dlaczego?
Spójrzmy na zwykłą operację odczytu danego elementu z tablicy. Dzięki temu, że kompilator języka C/C++ nie sprawdza granic tablicy, odchodzi cała zabawa związana ze sprawdzaniem tego faktu. Program zajmuje mniej miejsca i szybciej się wykonuje. Tak samo wygląda sytuacja z przepełnieniem zmiennych. Kompilator nie musi martwić się o to, że trzeba jakoś pozytywnie zareagować na tę sytuację. Zabezpieczeniem przed takimi błędami powinien martwić się programista.
Nie zapominajmy, że niektóre języki takie jak Java, są w tym względzie o wiele bardziej restrykcyjne niż C++. W Javie wszelkie niebezpieczne zachowania prowadzą do wyrzucenia odpowiednich wyjątków, które najczęściej przerywają działanie programu (chyba że programista zadecyduje inaczej. To był jeden z powodów przez które na początku swojej historii Java była wolniejsza od języków kompilowanych do kodu maszynowego. W dzisiejszych czasach różnica w wydajności jest praktycznie niezauważalna.
Dlaczego ignorujemy undefined behavior?
Najczęściej z powodu braku świadomości, że takie a nie inne rozwiązanie może doprowadzić do tragedii. Jeśli program wykonuje się prawidłowo – go on, przecież wszystko jest ok. No nie do końca.
Co może się wydarzyć kiedy napiszemy program wykorzystujący undefined behavior i spróbujemy go skompilować a następnie uruchomić? Dosłownie wszystko! Program może działać całkowicie prawidłowo, wykładając się jedynie w ściśle określonych sytuacjach. Aplikacja może się uruchomić. Lecz po uruchomieniu może działać źle, błędnie wykonując obliczenia. W najlepszej możliwej sytuacji kompilator poinformuje nas za pomocą ostrzeżenia lub błędu, że zrobiliśmy coś, co może zakończyć się źle.
Typy „zachowania”
Ogólnie zachowanie i sposób wykonania funkcji/metod możemy podzielić na trzy „główne” rodzaje:
- Typ 1 – zachowanie jest zdefiniowane dla każdego możliwego zbioru parametrów wejściowych
- Typ 2 – zachowanie jest zdefiniowane tylko dla niektórych zbiorów parametrów wejściowych
- Typ 3 – zachowanie jest niezdefiniowane dla wszystkich możliwych parametrów wejściowych
Aby nie lać wody, przeanalizujemy krótko i konkretnie każdą z wymienionych możliwości.
Funkcje typu 1
Funkcje tego typu nigdy nie mają problemów ze sobą i zawsze się prawidłowo wykonują. Spójrz np.: na taki przykład:
1 2 3 4 5 6 7 8 | int safeDiv (int a, int b) { if ((b == 0) || ((a == INT_MIN) && (b == -1))) { puts("Nie wolno tak dzielic!!!"); return 0; } else { return a / b; } } |
Z lekcji matematyki wiemy, że nie wolno dzielić przez 0. Zabezpieczyliśmy także program przed przepełnieniem zmiennej. Odpowiada za to druga część warunku.
W sumie, omawiając temat niezdefiniowanego zachowania tego typu funkcje nie są dla nas ciekawe.
Funkcje typu 3
Funkcje tego typu w każdym wypadku mogą spowodować dziwne zachowanie. Prostym przykładem jest niepoprawnie zastosowany operator przesunięcia arytmetycznego.
1 2 3 4 5 6 7 8 9 | #include <iostream> using namespace std; int main() { int a = 1; a=a<<32; cout<<a<<endl; return 0; } |
Teoretycznie program nie wykonuje żadnych niepożądanych operacji. Można rzec – jest prosty jak budowa cepa. Jego jedynym efektem powinno być przesunięcie bitowe wartości zmiennej a o 32 bity w lewo.
Jakiego wyniku się spodziewamy? Wydaje się, że program powinien wyświetlić liczbę 0. Przewidujemy taki rezultat, gdyż skrajne bity są tracone przy przesunięciu. Przesuwamy o 32 bity, a więc o większą ilość niż wynosi rozmiar zmiennej int. Z tego założenia wynika że wszystkie bity powinny być stracone a ostateczna wartość zmiennej powinna wynosić 0.
Kompilujemy i uruchamiamy program i …
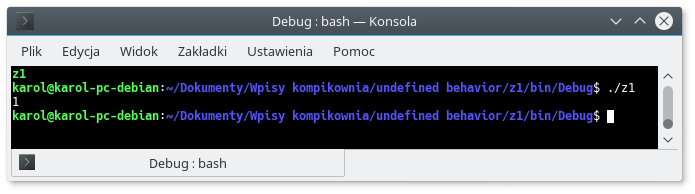
zonk. Wartość wynosi 1. Dlaczego? Zajrzyjmy do standardu języka C:
The result is undefined if the right operand is negative, or greater than or equal to the number of bits in the left expression’s type.
A teraz zerknijmy jeszcze na dokumentację procesora 8086 – przodka wszystkich współczesnych CPU architektury x86.
The 8086 does not mask the shift count. However, all other IA-32 processors (starting with the Intel 286 processor) do mask the shift count to 5 bits, resulting in a maximum count of 31. This masking is done in all operating modes (including the virtual-8086 mode) to reduce the maximum execution time of the instructions.
Jak widzisz, taki a nie inny wynik działania programu zależy w tym wypadku wyłącznie od zachowania procesora, a nie od woli programisty. Aby udowodnić, że powyższy program może zachowywać się różnie w zależności od architektury CPU uruchommy go na Raspberry PI – typowym przedstawicielu architektury ARM.
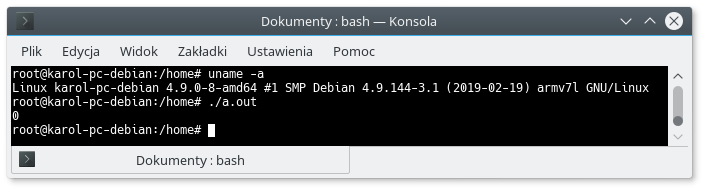
Tym razem identyczny program zwrócił wartość 0. Dowodzi to, że musimy uważać na działania, które są określone jako „undefined”.
Funkcje typu 2
Dla tych funkcji „undefined behavior” może wystąpić tylko dla niektórych danych wejściowych. Jest to najciekawszy przypadek dla nas. Jednocześnie takie błędy najtrudniej zauważyć. Przeanalizujmy co robi funkcja f w poniższym listingu.
1 2 3 4 5 6 7 8 9 10 11 12 13 | #include <iostream> #include <limits.h> using namespace std; int f(int i) { return i+1 > i; } int main() { int a = 1; int b = f(a); cout<<b<<endl; return 0; } |
Potencjalnie nie widzimy nic niebezpiecznego ani wieloznacznego. Funkcja wykonuje bardzo prostą operację. Sprawdzamy czy wartość parametru zwiększona o jeden jest większa od tego parametru. Wydaje się, że powinna ona zawsze zwrócić wartość 1. W końcu każda liczba jest mniejsza od tej samej liczby powiększonej o 1, prawda? Ale nie jest to takie proste mój kamracie. Zauważ, że jeśli przekażemy jako argument INT_MAX (czyli maksymalną wartość, jaką może pomieścić typ int) i zwiększymy ją o 1 otrzymamy liczbę dużo mniejszą. Wtedy funkcja ta zwróci false.
Jeśli skompilujemy program z tą funkcją bez włączonych optymalizacji za pomocą kompilatora gcc, nie nastąpią żadne problemy. Aplikacja będzie działała prawidłowo dla każdego przypadku. Nawet wtedy, gdy jako argument tej funkcji podamy wartość INT_MAX. Spójrzmy na kod assemblera, który został wygenerowany w finalnym pliku wykonywalnym:
mov rbp,rsp
mov DWORD PTR [rbp-0x4],edi
mov eax,DWORD PTR [rbp-0x4]
add eax,0x1
cmp eax,DWORD PTR [rbp-0x4]
setg al
movzx eax,al
pop rbp
ret
Kod wygląda tak jak przypuszczaliśmy. W rejestrze EAX przechowywany jest argument funkcji. Zwiększamy ten argument o 1 i porównujemy. Zwracamy wynik porównania. Kompilator wygenerował zbiór takich instrukcji, jakich oczekiwaliśmy. Jednakże co się stanie, gdy włączymy optymalizację na maksymalnym poziomie: O3? Co się zmieniło w kodzie ASM?
ret
Hmmm. Kompilator na pewno optymalizował ten kod. Możemy powiedzieć, że nawet przesadził z optymalizacją, gdyż wywalił całkowicie sprawdzanie warunku mniejsze/większe. Widocznie uznał, że jeden przypadek, kiedy funkcja zwraca inną wartość niż 1 można pominąć … Ta optymalizacja powoduje, że program dla INT_MAX zwróci inny wynik niż ten którego byśmy oczekiwali. Możesz nie rozumieć kodu ASM, więc przedstawię jak wyglądałaby funkcja f w postaci zoptymalizowanej prze kompilator:
return 1;
}
Prawda, że nie o to nam chodziło? A jak standard zapatruje się na to, co przed chwilą się wydarzyło? Otóż – jest to standardowy przypadek tzw. „integer overflow”.
If an exceptional condition occurs during the evaluation of an expression (that is, if the result is not mathematically defined or not in the range of representable values for its type), the behavior is undefined.
No cóż. Jedynym rozwiązaniem jest dodanie instrukcji warunkowej zabezpieczającej program przed podaniem argumentu INT_MAX, a tym samym przed przepełnieniem zmiennej integer.
Jak zapobiegać undefined behavior?
Undefined behavior jest czymś takim, czego powinniśmy unikać za wszelką cenę. Błędy tego rodzaju są nierzadko bardzo ciężkie do zdebugowania i wykrycia. Zdarzają się sytuacje, kiedy aplikacja pod debuggerem wykonuje się prawidłowo, a samodzielnie sypie błędami … Naprawdę zatruwa to życie programisty. Dlatego warto wiedzieć skąd bierze się undefined behavior. A jak możemy mu zapobiec?
- Pozwól kompilatorowi, aby informował cię nawet o bardzo błahych odstępstwach od standardu. W GCC włączysz tę opcję za pomocą przełączników: -Wall i -Wextra.
- Pozwól programowi przerwać swoje działanie kiedy wystąpi niezdefiniowana sytuacja wynikająca z operacji na liczbach, której nie przewidziałeś. Użyj przełącznika -ftrapv.
- Używaj analizatorów pokroju „valgrind”. Pomogą ci nie tylko wykryć wycieki pamięci, ale także sytuacje prowadzące do undefined behavior.
- Kiedy tworzysz funkcje „typu drugiego” pamiętaj o stworzeniu warunków które zapobiegną powstaniu niezdefiniowanego zachowania.
- Używaj asercji. To bardzo dobry wynalazek. Sprawia, że możesz być spokojny o to, że twój program wykonuje się prawidłowo. (podczas debugowania)
- Nie wymyślaj koła na nowo. Nie implementuj list, vectorów, jeśli takie struktury są dostępne w standardzie. Nie baw się tablicami w stylu języka C (int tab[]) skoro możesz używać typu vector lub w ostateczności array.
Undefined behavior jest bardzo niebezpieczne
Undefined behavior jest nieodłączną cechą języka C/C++, której nie pozbędziemy się jeszcze długo. Musimy nauczyć się z nim żyć. Undefined behavior powinniśmy unikać za wszelką cenę. Inaczej nie możemy być pewni (co zostało udowodnione powyżej) jaki kod wynikowy wygeneruje kompilator 🙂
Opracowanie stworzyłem na podstawie artykułu dostępnego pod tym linkiem:
Jeśli artykuł ci się podobał, polub mój profil na Facebooku 🙂 Jeśli chcesz być na bieżąco z wpisami na blogu, kliknij taki dziwny czerwono-biały dzwonek w lewej dolnej części strony i zezwól na wysyłanie notyfikacji.
Jeśli zauważyłeś jakieś błędy czy nieścisłości – śmiało – napisz komentarz. Jestem otwarty na krytykę 🙂
Czumu piszesz że w dzisiejszych czasach różnica w wydajności programu pisanego w Javie i C++ jest prawie niezauważalna. Kod pisany w C++ nadal wykouje się dużo szybciej od kodu pisanego w Javie.
No bo po pierwsze – mamy szybsze komputery.
Po drugie – nie ma porównania między dzisiejszą Javą a tą sprzed kilku lat pod względem szybkości. Choćby na Androidzie opartym o ART kod bajtowy Javy jest i tak kompilowany do kodu maszynowego, dzięki czemu wydajność jest taka sama jak w C++.