W poprzedniej części dowiedziałeś się czym są wątki oraz po co ich używać. Poznałeś także podstawową metodę synchronizacji, którą jest muteks, wprowadzony wraz z wersją C++11. Wierzę, że jest to ogrom przydatnej wiedzy, którą z pewnością kiedyś wykorzystasz. Zapoznaj się więc z kolejną częścią serii która sprawi, że praca z wątkami w C++ stanie się jeszcze przyjemniejsza. Będziesz popełniał także mniej brzemiennych w skutki błędów. Gotowy? No to zaczynajmy!
Wątki w C++, RAII i Zapominalski mutex.unlock()
Wiesz już jak działają muteksy. Przypomnijmy sobie pokrótce, jak wyglądałoby tworzenie sekcji krytycznej, do której dostęp ma tylko jeden wątek.
Musimy mieć jakiś obiekt klasy mutex, który jest współdzielony między wątkami. Na początku sekcji krytycznej używamy metody lock() tego mutexa. Na końcu „niebezpiecznego” obszaru umieszczamy wywołanie metody unlock obiektu muteksa.
std::mutex mut;
void sharedFunc() {
...
// ten kod może wykonać każdy wątek współbieżnie
mut.lock();
// sekcja krytyczna
mut.unlock()
}
...
Znasz już i rozumiesz użycie powyższego kodu, prawda? Jeśli nie, odsyłam do poprzedniego artykułu mówiącego o współbieżności w C++. Pomyślmy, jakie problemy mogą tu wystąpić?
Zakleszczenie – co to jest?
Najpopularniejszym problemem występującym wtedy, gdy korzystamy z wielu wątków i blokad jest zakleszczenie. Na czym ono polega?
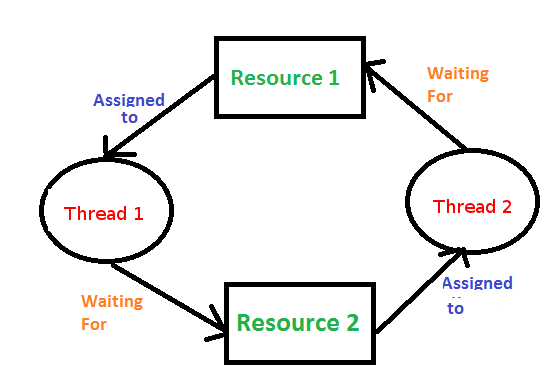
Spójrz na powyższy rysunek. Mamy w nim dwa zasoby. Uznajmy, że są to nasze sekcje krytyczne, czyli muteksy. Wątek pierwszy zajął sobie zasób pierwszy. W tej chwili nikt inny oprócz niego nie może z tego zasobu korzystać. Jednakże, do kontynuowania pracy wątek pierwszy potrzebuje zasobu drugiego. Tego zasobu nie może otrzymać, gdyż jest on przydzielony wątkowi drugiemu. Ten z kolei czeka na zasób pierwszy zajmowany, jak wiemy, przez wątek pierwszy. Taka cykliczna zależność nigdy się nie skończy. W przykładach pojawiających się w dalszej części tego artykułu niejednokrotnie zetkniemy się z problemem zakleszczeń i będziemy próbowali go rozwiązać najmniej radykalnie.
Brak zwolnienia muteksa – zakleszczenie
O czym możemy zapomnieć pisząc zaawansowaną aplikację wielowątkową? Oczywiście, o zwolnieniu muteksa, czyli użyciu metody unlock(). Co się stanie w takim wypadku? Program przestanie działać. Każdy następny wątek który dotrze do blokady nie będzie mógł wejść do sekcji krytycznej mimo iż ta jest pusta. Stanie się tak dlatego, gdyż system operacyjny nie zostanie poinformowany o zwolnieniu sekcji krytycznej przez pierwszy wątek. Ba! Możemy doprowadzić do sytuacji, że wątek będzie czekał sam na siebie! Spójrz np.: na taki kod:
#include <iostream>
#include <thread>
#include <mutex>
std::mutex mut;
void sharedFunc() {
for(int i = 0;i<10;i++) {
mut.lock();
std::cout<<"Obieg nr: "<<i<<std::endl;
}
}
int main() {
std::thread thr(sharedFunc);
thr.join();
return 0;
}
Uruchom powyższy program, klikając przycisk kompiluj. Nie przejmuj się tym, że wynik nie pojawia się od razu tylko po prostu poczekaj. Ujrzysz pewnie coś w stylu: „execution expired”. Program nie zdołał się wykonać w przeznaczonym dla niego limicie czasu. Dlaczego? Przeanalizujmy jego działanie. Wątek zaczyna wykonywanie funkcji sharedFunc. Wchodzi w pętlę for. Następnym krokiem jest wejście do sekcji krytycznej i zablokowanie muteksa mut. Odwołując się do rysunku przedstawionego wcześniej, możemy powiedzieć, że system operacyjny zarezerwował dla wątku zasób mut. Wątek kończy pierwszy obieg pętli. Zaczynamy kolejny obieg. System operacyjny już przydzielił wątkowi jedyną dostępną sztukę zasobu mut. Nie został on zwrócony do systemu, gdyż nie wywołaliśmy metody unlock. Teraz ten bezczelny wątek żąda jeszcze jednej sztuki zasobu! System operacyjny nie może jej w tej chwili przydzielić, więc wątek musi sobie poczekać. I będzie czekał tak w nieskończoność, gdyż oczekuje tak naprawdę sam na siebie! A konkretnie: na zasób, który sobie przydzielił i o którym zapomniał że go ma. Doprowadziliśmy do zakleszczenia.
Taki program można zamknąć jedynie brutalnymi metodami, takimi jak menedżer zadań w Windowsie czy polecenie kill w Linuksie. Mniej wprawny użytkownik naszej aplikacji mógłby się mocno wkurzyć, a tego przecież nie chcemy, prawda?
Wyjątki i muteksy w C++ – wybuchowa mieszanka
Z pewnością słyszałeś o wyjątkach. Są one bardzo fajną metodą obsługi błędów w języku C++. Problem powstaje, gdy sytuacja wyjątkowa występuje w sekcji krytycznej. W momencie wystąpienia wyjątku wykonanie funkcji jest przerywane. Zwolnić muteks musimy zatem nie tylko na końcu sekcji krytycznej, ale także w momencie obsługi wyjątku. Jeśli tego nie zrobimy, doprowadzimy do zakleszczenia. Spójrz na poniższy przykład:
#include <iostream>
#include <thread>
#include <mutex>
#include <chrono>
using std::cout;
using std::endl;
std::mutex mut;
void exceptionMutexTest(int id) {
std::this_thread::sleep_for(std::chrono::milliseconds(400));
try {
mut.lock();
cout<<"Wykonuję sekcję krytyczną dla id: "<<id<<endl;
std::this_thread::sleep_for(std::chrono::milliseconds(300));
if(id==1) throw "Wystąpił bardzo poważny problem";
mut.unlock();
}
catch(const char* p) {
cout<<"Wystąpił wyjątek dla wątku: "<<id<<" o treści: "<<p<<endl;
}
}
int main()
{
std::thread thr1(exceptionMutexTest,0);
std::this_thread::sleep_for(std::chrono::milliseconds(100));
std::thread thr2(exceptionMutexTest,1);
std::this_thread::sleep_for(std::chrono::milliseconds(100));
std::thread thr3(exceptionMutexTest,2);
thr1.join();
thr2.join();
thr3.join();
return 0;
}
Dostajemy po rękach znanym już błędem naszego środowiska wykonawczego: „execution expired”. Gdy wyjątki nie występują, wszystko działa prawidłowo. Wątek o ID=0 wykonuje swoją pracę do końca. Kłopoty zaczynają się, gdy swoje zadania zaczyna realizować kolejny wątek. Powoduje on wyjątek. Programista w obsłudze wyjątku zapomniał zwolnić blokadę muteksa. Skutki tak lekkomyślnego postępowania widać gdy do swojej pracy zabiera się kolejny wątek. Nie może on nawet zacząć swojej pracy, ponieważ poprzedni nie zwolnił blokady. Będziemy w stanie zakleszczenia i nic na to, jako użytkownicy programu nie poradzimy.
lock_guard – prosta metoda dla zapominalskich w C++
Jak w prosty sposób możemy rozwiązać wszystkie powyższe dolegliwości? Programista obciążony wieloma zadaniami może być zapominalski i nie należy dziwić się, że czasami zapomni po sobie posprzątać. Twórcy języka C++ to wiedzą i dlatego wprowadzają coraz więcej klas zgodnych ze wzorcem projektowym RAII (powiemy o nim więcej wkrótce)
Jedną z takich klas jest lock_guard. Co ona nam daje? Otóż, pilnuje aby muteks w odpowiednim momencie został zwolniony. Takie zwolnienie odbywa się wtedy, kiedy kończy się wykonanie danego bloku kodu. Spróbujmy zastosować ten przykład w praktyce:
#include <iostream>
#include <thread>
#include <mutex>
std::mutex mut;
void sharedFunc() {
for(int i = 0;i<10;i++) {
std::lock_guard<std::mutex> lock(mut);
std::cout<<"Obieg nr: "<<i<<std::endl;
}
}
int main() {
std::thread thr(sharedFunc);
thr.join();
return 0;
}
Zmiana nastąpiła w linijce 8. Użyliśmy nowego, wielokrotnie kilka razy wspominanego w tym rozdziale wspomagacza lock_guard. Uruchom powyższy program. Jak widzisz, wykonuje się teraz bez problemów. Słynny lock_guard pilnuje aby muteks został zwolniony za każdym razem, kiedy obieg pętli się kończy.
Co najważniejsze, lock_guard zwalnia muteks także wtedy, gdy wystąpi wyjątek 🙂 Przerób program z rozdziału Wyjątki i muteksy w C++ – wybuchowa mieszanka” tak, aby korzystał z lock_guard i sam przekonaj się, że to rzeczywiście działa.
Lock_guard niezastąpionym narzędziem obsługi muteksów w C++?
Jeśli pobawisz się chwilę lock_guardem, zauważysz, że brakuje mu kilku z poznanych do tej pory możliwości muteksów. Owszem, lock_guard pilnuje, aby blokada na muteksie została zarówno założona jak i zdjęta automatycznie. Ale zauważ, że tracimy tym samym możliwość ręcznego zarządzania stanem muteksa. Używając lock_guard, nie możemy jawnie wywołać metody unlock. Mówi o tym dokumentacja C++, której fragment przytaczam poniżej.

Lock_guard nie zawiera żadnych metod. Posiada jedynie konstruktor i destruktor.
Zastanówmy się, czy w ogóle potrzebujemy możliwości ręcznego blokowania i odblokowywania muteksów? Teoretycznie Lock_guard w 99% może nas zabezpieczyć przed jakimikolwiek sytuacjom hazardowym/niebezpiecznym. (O tym 1%, kiedy standardowy lock_guard nie okaże się skuteczny powiem w dalszej części artykułu). Ale jego użycie zabija jednocześnie optymalizację. A tym samym możemy utracić jedną z najważniejszych zalet wątków – możliwość współbieżnego wykonania. Dlaczego? Przeanalizuj poniższy listing.
void func() {
[1]... // kod, który może się wykonywać równocześnie w wielu wątkach bez blokad
[2] std::lock_guard<std::mutex> lock(mut);
[3]... // sekcja krytyczna, kod który może wykonywać tylko jeden wątek na raz
cout<<"Wynik operacji to: "<<...<<endl;
// w tym momencie nasza sekcja krytyczna się kończy, ale blokada nie zostaje zdjęta
[4]... // kod, który może wykonywać się równocześnie w wielu watkach bez blokad
}
Aby łatwiej było omówić powyższy przykład, podzieliłem go na sekcję, [1], [2], [3] i [4].
Funkcja func się uruchamia. Załóżmy, że jednocześnie wykonuje ją kilka wątków. Część oznaczoną jako [1] wszystkie wątki mogą wykonać współbieżnie. Żaden muteks czy inna blokada nie uniemożliwia takiej czynności. Dopiero gdy któryś wątek dotrze do [2] czyli utworzenia obiektu lock, blokada jest zakładana. Dalszą podróż odbędzie tylko jeden wątek a pozostałe są wstrzymywane w tym punkcie. Sekcja krytyczna obejmuje część [3]. Używając lock_guard nie mamy możliwości poinformowania systemu, że w momencie dotarcia do końca części 3 kończy się jednocześnie sekcja krytyczna. Mimo, że kod części [4] w żaden sposób nie koliduje z wykonaniem części w sekcji krytycznej, to pozostałe wątki są w dalszym ciągu wstrzymywane. Dopiero, gdy wątek aktualnie znajdujący się w sekcji krytycznej dotrze do końca funkcji, muteks zostanie odblokowany i następny wątek zacznie wykonywać swoją pracę.
Ach, tracimy tyle prędkości, marnujemy tyle mocy procesora. Dodatkowo, łamiemy naczelną zasadę mówiącą o tym że sekcja krytyczna powinna być tak mała jak to tylko możliwe. Czy naprawdę musimy wracać do zwykłych muteksów? Mamy co prawda nad nimi pełną kontrolę, ale są uciążliwe w użyciu i błędogenne. Czy rzeczywiście chcąc uzyskać najwyższą wydajność nie możemy korzystać z udogodnień w postaci automatycznego odblokowywania muteksu dostarczanego przez lock_guard? Otóż, niekoniecznie. Istnieje klasa która posiada zalety lock_guard, a jednocześnie pozwala na ręczne zarządzanie stanem muteksa. Poznaj: unique_lock.
unique_lock – i synchronizacja wątków staje się prostsza
Jak użyć unique_lock w synchronizacji wątków C++?
Jak użyć unique_lock? Zobaczysz to, jak przeanalizujemy poniższy kod:
#include <iostream>
#include <thread>
#include <mutex>
#include <chrono>
#include <vector>
#include <algorithm>
using std::cout;
using std::endl;
const int THREAD_COUNT = 3;
std::mutex mut;
void sharedFunc(int nr) {
std::this_thread::sleep_for(std::chrono::milliseconds(500)); // symulacja skomplikowanych operacji
cout<<"Watek: "<<nr<<" sekcja 1 ukończona"<<endl;
std::unique_lock<std::mutex> lock(mut);
std::this_thread::sleep_for(std::chrono::milliseconds(700)); // symulacja skomplikowanych operacji
cout<<"Wątek: "<<nr<<" sekcja 2 ukończona"<<endl;
lock.unlock();
std::this_thread::sleep_for(std::chrono::milliseconds(500)); // symulacja skomplikowanych operacji
cout<<"Wątek: "<<nr<<" sekcja 3 ukończona"<<endl;
}
int main() {
auto start = std::chrono::system_clock::now();
std::vector<std::thread> threads;
for(int i = 0;i<THREAD_COUNT;i++) {
threads.push_back(std::thread(sharedFunc,i));
}
for_each(threads.begin(),threads.end(),[](std::thread& v)->void{v.join();});
auto end = std::chrono::system_clock::now();
cout<<"Program wykonywał się :"<<std::chrono::duration_cast<std::chrono::milliseconds>(end-start).count()<<" milisekund"<<endl;
return 0;
}
Uruchom powyższy program. Algorytm jest taki sam jak w poprzednim rozdziale, w którym omawialiśmy jedną z podstawowych wad lock_guard. Jedyna różnica jest taka, że zastąpiliśmy lock_guard unique_lockiem. Spójrz na linijkę 14. Właśnie w tamtym miejscu tworzymy obiekt unique_lock. Tutaj także jest zakładana jest blokada. W linijce 17 zdejmujemy blokadę ręcznie. Dzięki temu gdy wątek A opuści sekcję krytyczną, oczekujący wątek B może do niej natychmiastowo wejść, mimo iż wątek A nie doszedł jeszcze do końca funkcji sharedFunc. Zauważysz to także po wynikach działania programu, jeśli go uruchomisz.
A co jeśli usuniemy linijkę 17? Nic się nie stanie. Wtedy unique_lock zachowa się dokładnie w taki sam sposób, w jaki zachowałby się lock_guard – zdejmie blokadę muteksa w momencie kiedy wątek dojdzie do końca funkcji. Spróbuj i przekonaj się sam!
Spójrz na różnicę czasów. Gdy zastosowaliśmy optymalizację z użyciem unique_lock, program wykonywał się ok. 3100 milisekund. Gdybyśmy użyli lock_guard, program wykona się w czasie ok. 4100 milisekund. Różnica będzie rosła wraz ze wzrostem liczby wątków.
Kiedy musimy użyć unique_lock?
Istnieje kilka przypadków, kiedy najprostszym możliwym wspomagaczem, którego możemy użyć, jest unique_lock. Wyobraź sobie następującą sytuację.
Tworzymy aplikację dla banku. Mamy miliony klientów. Siłą rzeczy musimy wykorzystywać całą moc dostępnych maszyn. Musimy wykonać przelew z jednego konta na drugie. Pieniądze są rzeczą wrażliwą i nie chcemy, aby pojawiły się jakiekolwiek problemy typu: zdublowane pieniądze na jednym z kont itd. Musimy zabezpieczyć taką operację za pomocą blokad. Jak byśmy to zrobili używając lock_guard?
#include <iostream>
#include <thread>
#include <mutex>
#include <chrono>
using std::cout;
using std::endl;
class BankAccount {
public:
BankAccount(int __balance) : balance(__balance) {}
void transferFrom(BankAccount& from, int value) {
// musimy zablokować obydwa muteksy, gdyż każdy transfer bankAccount uruchomiony jest w oddzielnym wątku
std::lock_guard<std::mutex> lock1(from.mut);
std::this_thread::sleep_for(std::chrono::milliseconds(300)); // załóżmy, że coś w tej chwili jest wykonywane
std::lock_guard<std::mutex> lock2(mut);
from.balance -= value;
balance += value;
}
int getBalance() {return balance;}
private:
int balance;
std::mutex mut;
// inne rzeczy
};
int main()
{
BankAccount b1(400);
cout<<"Konto pierwsze ma : "<<b1.getBalance()<<" PLN środków"<<endl;
BankAccount b2(500);
cout<<"Konto drugie ma : "<<b2.getBalance()<<" PLN środków"<<endl;
std::thread thr1(&BankAccount::transferFrom,std::ref(b1),std::ref(b2),100);
std::thread thr2(&BankAccount::transferFrom,std::ref(b2),std::ref(b1),200);
thr1.join();
thr2.join();
cout<<endl<<"Po operacjach"<<endl;
cout<<"Konto pierwsze ma : "<<b1.getBalance()<<" PLN środków"<<endl;
cout<<"Konto drugie ma : "<<b2.getBalance()<<" PLN środków"<<endl;
return 0;
}
Zarządzaniem kontami zajmuje się klasa BankAccount. Metoda transferFrom pozwala na bezkonfliktowe przeniesienie pieniędzy z innego konta na aktualne. Z każdym kontem powiązany jest muteks, który w momencie operowania na danym koncie powinien być zablokowany Transfer pieniędzy z jednego konta na drugie modyfikuje bilans na obydwu kontach. W związku z tym musimy zablokować obydwa muteksy. Linijka 13, w której znajduje się sleep_for, symuluje dodatkowe operacje związane z zapewnieniem wyłącznego dostępu do danego konta.
Uruchom powyższy program. Co się dzieje? Dostajemy komunikat: execution expired. Oznacza to, że w którymś miejscu doszło do zakleszczenia. Co się mogło stać?
Spójrz na linijki 12, 13 i 14. Pierwszy wątek zakłada blokadę na konto drugie oraz wykonuje swoje związane z tym operacje. Następnie blokada zakładana jest na konto pierwsze. Drugi wątek wykonuje takie same czynności ,tylko w odwrotnej kolejności. Dochodzi do zakleszczenia. Pierwszy wątek już zablokował obydwa muteksy w momencie, kiedy drugi wątek próbuje uzyskać wyłączność. Tym samym obydwa wątki czekają na siebie nawzajem i raczej nigdy się nie doczekają 🙁 Do kosza z tym rozwiązaniem. (Na samym końcu tego artykułu pokażę, jak można użyć lock_guard, aby powyższy program działał)
Jak rozwiązać ten problem? Musimy użyć unique_lock oraz jednej z trzech specjalistycznych strategii blokujących: defer_lock.
unique_lock i defer_lock – rozwiązujemy problem zakleszczenia
#include <iostream>
#include <thread>
#include <mutex>
#include <chrono>
using std::cout;
using std::endl;
class BankAccount {
public:
BankAccount(int __balance) : balance(__balance) {}
void transferFrom(BankAccount& from, int value) {
// musimy zablokować obydwa muteksy, gdyż każdy transfer bankAccount uruchomiony jest w oddzielnym wątku
std::unique_lock<std::mutex> lock1(from.mut,std::defer_lock);
std::this_thread::sleep_for(std::chrono::milliseconds(300)); // załóżmy, że coś w tej chwili jest wykonywane
std::unique_lock<std::mutex> lock2(mut,std::defer_lock);
std::lock(lock1,lock2);
from.balance -= value;
balance += value;
}
int getBalance() {return balance;}
private:
int balance;
std::mutex mut;
// inne rzeczy
};
int main()
{
BankAccount b1(400);
cout<<"Konto pierwsze ma : "<<b1.getBalance()<<" PLN środków"<<endl;
BankAccount b2(500);
cout<<"Konto drugie ma : "<<b2.getBalance()<<" PLN środków"<<endl;
std::thread thr1(&BankAccount::transferFrom,std::ref(b1),std::ref(b2),100);
std::thread thr2(&BankAccount::transferFrom,std::ref(b2),std::ref(b1),200);
thr1.join();
thr2.join();
cout<<endl<<"Po operacjach"<<endl;
cout<<"Konto pierwsze ma : "<<b1.getBalance()<<" PLN środków"<<endl;
cout<<"Konto drugie ma : "<<b2.getBalance()<<" PLN środków"<<endl;
return 0;
}
Co zmieniło się w kodzie? W sumie niewiele. Linijka 12 i 14 się zmieniła. Wcześniej używaliśmy lock_guard, a teraz używamy unique_lock. W przeciwieństwie do poprzednich przykładów, podaliśmy konstruktorowi dodatkowy argument: std::defer_lock. Co to jest? Otóż, jest to jedna z trzech dostępnych strategii blokowania. std::defer_lock zapewnia, że blokada nie zostanie zalożona wraz z utworzeniem obiektu unique_lock. Nie tracimy jednakże możliwości zwolnienia blokady wraz z końcem bloku kodu.
Blokadę zakładamy ręcznie w linijce 15. Służy do tego specjalna funkcja: lock. Czym różni się od ręcznego blokowania muteksa za pomocą wbudowanej w niego metody lock? Funkcja lock zapewnia, że wszystkie muteksy podane jako argumenty funkcji lock zostaną zablokowane, przy czym nigdy nie powstanie zakleszczenie.
Dzięki temu nasz stworzony przed chwilą bank może prawidłowo działać 🙂
Strategie blokujące
Z poprzedniego rozdziału dowiedzieliśmy się, że możemy modyfikować zachowanie niektórych klas blokujących, takich jak unique_lock. Mamy do wyboru następujące rodzaje zachowań:
- Zachowanie domyśłne – blokada zakładana jest w chwili utworzenia obiektu i zdejmowana w chwili opuszczenia bloku kodu/funkcji/metody
- std::defer_lock – nie zakłada blokady przy tworzeniu obiektu
- std::try_to_lock – próbuje założyć blokadę. Wynik możemy sprawdzić za pomocą metody owns_lock. Zaletą zastosowania tej strategii jest to, że wątek może zająć się inną pracą w chwili, gdy nie udało mu się dostać do sekcji krytycznej.
- std::adopt_lock – przyjmuje, że blokada została założona przez aktualnie wykonywany wątek. Strategia ta jedynie przejmuje kontrolę nad muteksem dbając o to, aby został w odpowiedniej chwili zwolniony.
std::adopt_lock – przykład użycia
Obiecałem, że pokażę jak przerobić przykład z bankiem tak, abyśmy mogli użyć lock_guard. Otóż, podobnie jak możemy zmienić zachowanie unique_lock, tak samo możemy wpłynąć na działanie lock_guard. Domyślne zachowanie, jak już udowodniliśmy, nie sprawdzi się. A co, jeśli użylibyśmy strategii adopt_lock? Zobaczmy
#include <iostream>
#include <thread>
#include <mutex>
#include <chrono>
using std::cout;
using std::endl;
class BankAccount {
public:
BankAccount(int __balance) : balance(__balance) {}
void transferFrom(BankAccount& from, int value) {
// musimy zablokować obydwa muteksy, gdyż każdy transfer bankAccount uruchomiony jest w oddzielnym wątku
std::lock(from.mut,mut);
std::lock_guard<std::mutex> lock2(mut,std::adopt_lock);
std::this_thread::sleep_for(std::chrono::milliseconds(300)); // załóżmy, że coś w tej chwili jest wykonywane
std::lock_guard<std::mutex> lock1(from.mut,std::adopt_lock);
from.balance -= value;
balance += value;
}
int getBalance() {return balance;}
private:
int balance;
std::mutex mut;
// inne rzeczy
};
int main()
{
BankAccount b1(400);
cout<<"Konto pierwsze ma : "<<b1.getBalance()<<" PLN środków"<<endl;
BankAccount b2(500);
cout<<"Konto drugie ma : "<<b2.getBalance()<<" PLN środków"<<endl;
std::thread thr1(&BankAccount::transferFrom,std::ref(b1),std::ref(b2),100);
std::thread thr2(&BankAccount::transferFrom,std::ref(b2),std::ref(b1),200);
thr1.join();
thr2.join();
cout<<endl<<"Po operacjach"<<endl;
cout<<"Konto pierwsze ma : "<<b1.getBalance()<<" PLN środków"<<endl;
cout<<"Konto drugie ma : "<<b2.getBalance()<<" PLN środków"<<endl;
return 0;
}
Jak zachowują się blokady w tym wypadku? Używamy funkcji lock, tym razem bezpośrednio na muteksach (linijka 12). Funkcja ta zablokuje obydwa muteksy dla wątku tak, aby nie wystąpiło zakleszczenie. W kolejnej linijce mamy utworzenie obiektu klasy lock_guard. Tym razem jednakże stosujemy strategię adopt_lock. Lock_guard nie próbuje założyć blokady, gdyż ta została wcześniej założona ręcznie przez funkcję lock. Wg obranej strategii, próbuje natomiast „adoptować” muteks, przejąć nad nim kontrolę. Blokada jest założona. Lock_guard będzie dbał tylko o to, aby została zwolniona. Podobne zadanie pełni linijka 15 w odniesieniu do drugiego muteksu.
std::try_lock – przykład użycia
#include <iostream>
#include <thread>
#include <mutex>
#include <chrono>
#include <vector>
#include <algorithm>
const int THREAD_COUNT = 3;
std::mutex mut;
std::mutex mut2;
using std::cout;
using std::endl;
int doneWork = 0;
int otherWork = 0;
void exampleFunc(int i) {
int result = 0;
int actualThreadWork = 0;
while(result==0) {
std::unique_lock<std::mutex> lock(mut,std::try_to_lock);
if(lock.owns_lock()) {
cout<<"Wątek :"<<i<<" posiada wyłączność. Wykonuję akcje"<<endl;
std::this_thread::sleep_for(std::chrono::milliseconds(400));
result++;
doneWork++;
otherWork += actualThreadWork;
cout<<"Pracę wykonało: "<<doneWork<<" wątków"<<endl;
cout<<"Inna praca została do tej pory wykonana: "<<otherWork<<" razy"<<endl;
}
else {
cout<<"Wątek "<<i<<" oczekuje na wejście. Tymczasem robi coś innego "<<endl;
std::this_thread::sleep_for(std::chrono::milliseconds(300));
actualThreadWork++;
cout<<"Inna praca wątku: "<<i<<" została wykonana: "<<actualThreadWork<<" razy"<<endl;
}
}
}
int main()
{
std::vector<std::thread> threads;
for(int i = 0;i<THREAD_COUNT;i++) {
threads.push_back(std::thread(exampleFunc,i));
}
for_each(threads.begin(),threads.end(),[](std::thread& v)->void{v.join();});
return 0;
}
Powyższy przykład prezentuje użycie strategii try_to_lock. Naszą funkcją, którą wykonuje każdy z wątków jest exampleFunc. Gdy wątkowi uda się uzyskać dostęp na wyłączność, modyfikowane są globalne zmienne doneWork i otherWork. W przypadku, gdy wyłączności nie uda się uzyskać, wątek modyfikuje sobie lokalne zmienne. Zmiana lokalnych zmiennych jest bezpieczna, gdyż należą one tylko do danego wątku. Tym samym oszczędzamy czas i możemy przyspieszyć obliczenia, które wykonuje nasz program. Oczywiście, mimo zmiany strategii, unique_lock zachowuje swoją główną zaletę – zwalnia blokadę w momencie, gdy wątek opuści blok kodu funkcji.
Podsumowując
Poznałeś dzisiaj dużo bardzo ciekawej i przydatnej wiedzy. Unique_lock i lock_guard znacznie ułatwiają i przyspieszają tworzenie programów współbieżnych. Dowiedziałeś się także o różnych strategiach, które pozwalają modyfikować zachowanie zarówno unique_lock oraz lock_guard w taki sposób, aby jak najlepiej współpracowały z twoim algorytmem.
Pisząc swoje własne programy pamiętaj o tym, aby jak najrzadziej (nigdy) nie używać gołych muteksów. Jeśli tylko się da, używaj lock_guard, gdyż jest on „najlżejszy” i najszybszy. W pozostałych wypadkach dobrym rozwiązaniem będzie unique_lock.
Jeśli masz jakieś pytania czy uwagi, pisz 🙂 W kolejnej części zajmiemy się typowymi, omawianymi przez literaturę problemami synchronizacji wątków, czyli praktycznym podejściem do zdobytej dzisiaj wiedzy.