Programując w C++, z pewnością wiesz jak inicjuje się zmienne. Nie jest to czynność skomplikowana. Trochę więcej problemów zachodzi kiedy musisz zainicjować tablicę lub jakiś kontener. Stosujesz wtedy pewnie pętlę for. Jeśli musisz dodać kilka lub kilkanaście elementów do kontenera vector, stosujesz metodę push_back, wywołując ją ręcznie albo w pętli. Nie jest to rozwiązanie złe – gdyż działa. Jednakże, standard C++11 wprowadził w tym względzie duże udogodnienie. Jest nim tzw. „uniform initialization”. Po polsku można byłoby to przetłumaczyć jako „jednolita inicjalizacja”.
Jak wygląda uniform initialization?
W starszym C++ znajduje się dużo różnorodności. Inaczej zainicjujemy element klasy, inaczej wypełnimy zwykłą tablicę o stałym rozmiarze a inaczej kontener vector. Spójrz na poniższy przykład, napisany w starym C++.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | #include <iostream> #include <vector> #include <list> #include <map> using namespace std; int main() { int tab[] = {1,2,3,4,5}; list<int> normal_list; for(int i = 0;i<5;i++) normal_list.push_front(i+1); map<int,string> normal_map; normal_map[0] = "zero"; normal_map[1] = "one"; normal_map[20] = "two"; vector<int> vec; vec.push_back(100); vec.push_back(200); vec.push_back(300); return 0; } |
Zobacz wielorakość form inicjacji poszczególnych rodzajów zmiennych, tablic czy kontenerów. Do wypełnienia zwykłej tablicy używamy nawiasów klamrowych. Lecz w przypadku listy używamy pętli z metodą push_front. Mapę wypełniamy treścią w jeszcze inny sposób. W końcu kontener vector – który używa metody push_back.
Czy nie dałoby się tego zrobić jakoś prościej? Spójrz, jak to można wykonać w C++11.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | #include <iostream> #include <vector> #include <list> #include <map> using namespace std; int main() { int tab[] {1,2,3,4,5}; list<int> normal_list {1,2,3,4,5}; map<int,string> normal_map {{0,"zero"},{1,"one"},{2,"two"}}; vector<int> normal_vector {100,200,300}; return 0; } |
Jak widzisz wypełniamy w ten sam sposób każdy rodzaj kontenera. Nie jest ważne czy to vector, zwykła tablica o określonym rozmiarze czy mapa. W każdym wypadku stosujemy nawiasy klamrowe, w których wypisujemy wartości które mają zostać dodane do kontenera.
Mógłbyś zapytać, jak fachowo nazywają się te nawiasy klamrowe? Zaspokoję twoją ciekawość. Jest to lista inicjalizacyjna. (Nie myl z listą inicjalizacyjną konstruktora).
Kluczowe różnice
W starszym standardzie C++ przy inicjacji zmiennych danymi wartościami istniały trzy różne przypadki:
- () – zwykłe nawiasy. Wykorzystywane wtedy, kiedy klasa posiada konstruktor, który zajmuje się przygotowaniem jej do pracy.
- {} – używany przy strukturach.
- Brak nawiasów – normalna inicjacja zmiennych, za pomocą operatora przypisania
- Specjalna metoda – np.: push_back w przypadku vector.
Teraz nie musimy się niczym przejmować. Przy wstępnym wypełnianiu kontenera/tablicy wartościami, możemy bezpiecznie używać nawiasów klamrowych {}. Każdy nowszy kompilator sobie z tym bez problemu poradzi.
Uniform initialization i klasy
Wskoczmy na nieco wyższy poziom. Zobaczmy, ile da nam uniform initialization przy klasach własnej produkcji. Zerknij na poniższy kod. Najpierw przeanalizuj go samodzielnie. Potem przewiniesz stronę i przeanalizujemy go wspólnie :).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | #include <iostream> #include <vector> #include <utility> using namespace std; struct Foo { int x; float y; }; class Bar { public: Bar(int _x,float _y) : x(_x),y(_y) {} private: int x; float y; }; pair<double,double> multiplyVectors(pair<double,double> v1,pair<double,double> v2) { return pair<double,double>(v1.first*v2.first,v1.second*v2.second); } int main() { //tworzenie obiektów za pomocą konstruktora domyślnego Foo fooObject; Foo fooObject2(); //tworzenie obiektów za pomocą konstruktora własnego Foo FooObjectAggregate {3,3.5f}; Bar BarObjectWithConstructor(3,3.5f); //trochę zabawy z vectorami vector<Bar> vectorOfBars; vectorOfBars.push_back(Bar(1,1)); vectorOfBars.push_back(Bar(2,2)); vectorOfBars.push_back(Bar(3,3)); pair<double,double> result = multiplyVectors(pair<double,double>(2.0,2.0),pair<double,double>(3.0,4.0)); //Tablice Foo arrOfFoos[] = {{1,1.0f},{2,2.0f},{3,3.0f}}; Bar arrOfBars[] = {Bar(1,1.0f),Bar(2,2.0f),Bar(3,3.0f)}; return 0; } |
Tworzymy sobie strukturę Foo i klasę Bar. (linijki 5-15). Tworzymy sobie także prostą funkcję, która z pomocą pair pozwala nam na pomnożenie dwóch wektorów (tych matematycznych :)).
W linijkach 22 i 23 tworzymy obiekt klasy Foo. Pierwszy sposób (22) tworzy obiekt wypełniony domyślnymi wartościami. Drugi natomiast jest o wiele bardziej problematyczny. Spodziewałbyś się pewnie, że zostanie utworzona zmienna o nazwie fooObject2 typu Foo. Tak się jednak nie stanie. Linijka ta wygląda jak wywołanie konstruktora domyślnego – to fakt. W rzeczywistości jednak jest do deklaracja funkcji, która zwraca Foo i nie przyjmuje żadnych argumentów. Gdybyśmy spróbowali odwołać się do zmiennej x lub y obiektu fooObject2, nie uda nam się to.
W linijce 26 i 27 możemy wykonać kolejne porównanie. Strukturę możemy wypełnić za pomocą listy inicjalizacyjnej. Jednakże, dla klasy musimy wywołać konstruktor.
Zobaczmy, jak możemy dodać obiekty naszej klasy do kontenera vector. No cóż, wygląda to standardowo, co ukazują linijki 30-33. Za każdym razem musimy wywoływać metodę push_back. Następnie, jako argument podajemy konstruktor obiektu z określonymi argumentami.
Funkcja – linijka 34. Możesz przeanalizować także jej definicję w linijkach 16-17. Funkcja ta praktycznie nic nie robi. Mimo tego, jest bardzo rozwlekła. Czy uniform initialization i listy inicjalizacyjne mogą tu coś pomóc? Zobaczmy.
Wykorzystajmy uniform initializationn
Spójrz na poniższy kod. Następnie porównaj go z tym z poprzedniego akapitu i wskaż różnice.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | #include <iostream> #include <vector> #include <utility> using namespace std; struct Foo { int x; float y; }; class Bar { public: Bar(int _x,float _y) : x(_x),y(_y) {} private: int x; float y; }; pair<double,double> multiplyVectors(pair<double,double> v1,pair<double,double> v2) { return {v1.first*v2.first,v1.second*v2.second}; } int main() { //tworzenie obiektów za pomocą konstruktora domyślnego Foo fooObject {}; //tworzenie obiektów za pomocą konstruktora własnego Foo FooObjectAggregate {3,3.5f}; Bar BarObjectWithConstructor{3,3.5f}; //trochę zabawy z vectorami vector<Bar> vectorOfBars {{1,1},{2,2},{3,3}}; auto result = multiplyVectors({2.0,2.0},{3.0,3.0}); //Tablice Foo arrOfFoos[] = {{1,1.0f},{2,2.0f},{3,3.0f}}; Bar arrOfBars[] = {{1,1.0f},{2,2.0f},{3,3.0f}}; return 0; } |
Zauważyłeś pewnie, że jest o wiele prościej. A przede wszystkim – bardziej jednolicie. Przeanalizujmy po kolei zmiany.
Linijka 22 – tworzymy obiekt struktury Foo za pomocą pustej listy inicjalizacyjnej. Dodatkowo, rozwiązuje nam to problem niejednoznaczności. Pamiętasz dylemat z poprzedniego przykładu, gdzie zastanawialiśmy się czy mamy do czynienia ze zwykłą definicją zmiennej czy deklaracją funkcji? Używając uniform initialization, nie mamy takich dylematów.
Linijka 24 i 25. Obydwa rodzaje – zarówno strukturę jak i klasę z przeciążonym konstruktorem możemy wypełnić tak samo – za pomocą listy inicjalizacyjnej.
Linijka 28. To tutaj najbardziej skróciliśmy kod. Nie ma już wywołań metody push_back. Wszystkie trzy elementy dodajemy w jednej linijce.
Linijka 29. Tutaj również zauważymy spore uproszczenie. Nie ma tego elementu który najbardziej wydłużał nam tę linijkę – ciągłego powtarzania pair<double,double>. Wynik zwracany za pomocą tej funkcji zapisujemy do zmiennej o typie auto. Dzięki auto kompilator sam się domyśli, jakiego rodzaju zmienną powinien utworzyć. Natomiast w liście argumentów używamy listy inicjalizacyjnej do stworzenia obiektów pair i przekazania ich do funkcji.
Zostały nam tablice. No cóż. Nie ma tutaj wiele do omówienia. Nie ważne czy to struktura czy to klasa. Możemy użyć nawiasów klamrowych do wypełnienia jej wartościami. Kompilator sam domyśli się, którego konstruktora użyć w przypadku klasy.
Zauważyłeś gdzie jeszcze użyłem uniform initialization? Spójrz na linijkę 17. Zwracając wynik, nie tworzymy obiektu pair jawnie. Kreujemy go niejawnie, używając listy inicjalizacyjnej. Dzięki temu uzyskaliśmy znaczne skrócenie zapisu.
Uniform initialization – Niejednoznaczności
Uniform Initialization czasami potrafi nam przysporzyć nieco problemów. W przykładzie analizowanym w poprzednim akapicie utworzyliśmy klasę Bar. Miała ona konstruktor przyjmujący dwa parametry. Jak zauważyłeś, lista inicjalizacyjna korzystała z tego konstruktora do stworzenia obiektu. Lecz nie zawsze tak jest.
1 | vector<int> vec(400); |
Spójrz na tę powyższą, samotną linijkę kodu. Zastanów się i odpowiedz na pytanie.
Czy:
- doda do vectora vec wartość 400?
- utworzy vector o wstępnym rozmiarze 400?
Poprawną odpowiedzią jest odpowiedź druga. Lecz spójrz na to
1 | vector<int> vec {400} |
Co się teraz stanie? Na podstawie przykładów z poprzedniego akapitu odpowiesz, że teraz do vectora zostanie dodany element 400. Rzeczywiście, listy inicjalizacyjne nie zawsze korzystają z konstruktorów. A jak to wykorzystać?
Lista inicjalizacyjna we własnych klasach
Wiemy już jak używać list inicjalizacyjnych. Dowiedziałeś się, że domyślnie lista inicjalizacyjna używa konstruktora.Widziałeś klasę vector? Jak zrobić we własnej klasie taką sztuczkę, jaką stosuje vector? Nie jest to trudne. Spójrz na poniższy kod:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | #include <iostream> using namespace std; class IFoo { public: IFoo(int a) { this->x = a; this->y = a; this->z = a; } IFoo(initializer_list<int> l) { initializer_list<int>::iterator i = l.begin(); if(i!=l.end()) { x = *i; i++; } if(i!=l.end()) { y = *i; i++; } if(i!=l.end()) { z = *i; i++; } } void print() { cout<<"x: "<<x<<" y: "<<y<<" z: "<<z<<endl; } private: int x = 0; int y = 0; int z = 0; }; int main() { IFoo ob {1,2,3}; IFoo ob2 {1}; IFoo ob3(1); cout<<"ob: "; ob.print(); cout<<"ob2: "; ob2.print(); cout<<"ob3: "; ob3.print(); return 0; } |
Naszym obiektem badań stała się klasa IFoo. Mamy trzy składniki (zmienne) prywatne klasy: x,y,z. Konstruktor zadeklarowany i zdefiniowany w linijce 6 przypisuje tę samą wartość wszystkim składnikom klasy. Gdybyśmy nie dodawali obsługi listy inicjacyjnej, to przy jej użyciu właśnie ten konstruktor byłby wywołany.
Ale my byliśmy na tyle krnąbrni, że dodaliśmy do naszej klasy obsługę listy inicjalizacyjnej. Ta obsługa to nic innego jak zwykły konstruktor, który przyjmuje jako argument charakterystyczny parametr: initializer_list. Pomimo skomplikowanego wyglądu, nie jest to nic innego jak zwykły kontener, po którym możemy się poruszać za pomocą iteratorów. Ten konstruktor, który zaczyna się od linijki 11, przypisuje każdą kolejno podaną liczbę kolejnym składnikom klasy.
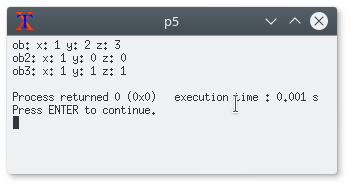
W funkcji main zaprezentowałem przykład użycia. Spójrz na wyjście programu. W rezultacie wszystko powinno stać się dla ciebie jasne.
Podsumowując – wady i zalety uniform initialization
Uniform initialization wprowadzony wraz z C++11 jest niezwykle przydatnym rozwiązaniem. Jego główną zaletą jest skrócenie kodu, co innymi słowy automatycznie poprawia jakość naszego kodu i pozwala na uniknięcie popełniania błędów. Błędów, które mogą być nieraz tragiczne w skutkach i spowodować wiele nieprzespanych nocy. Musimy jedynie uważać na pewne niejasności, kiedy dana klasa jawnie mówi jak będzie interpretować listę inicjalizacyjną.
Standardowo, wszystkie kody źródłowe umieszczone w tym wpisie znajdują się w moim repozytorium na portalu GitHub o, tutaj 🙂
Jeśli chciałbyś się podzielić swoją opinią, wal śmiało 🙂