W jednym z poprzednich artykułów opisałem, jak można w języku C zaprogramować stos. Z pewnością przy tworzeniu bardziej zaawansowanego projektu napotkasz na pewien problem: Co zrobić, jeśli chcesz posiadać kilka stosów, przechowujących różne rodzaje danych? W C++, Javie, C# i innych tego typu językach rozwiązanie tego problemu jest dosyć proste. Możemy stworzyć stos generyczny, czyli mogący przechowywać wybrany przez nas rodzaj danych. Niestety, zwykły C nie wspiera tego rodzaju ułatwiających życie programisty wynalazków. W C nie mamy typów generycznych, które pozwalałyby na łatwe utworzenie dynamicznej struktury danych mogącej przechowywać różne rodzaje danych.

Możemy oczywiście obyć się bez typów generycznych. Wystarczy stworzyć kilka rożnych rodzajów struktury stack_node. Każda z wersji przechowywałaby inny typ zmiennej w polu data. Rozwiązanie to niesie za sobą bardzo wiele wad. Po pierwsze – kod funkcji push i pop, który zmienia się w bardzo niewielkim stopniu dla poszczególnych rodzajów stosów będzie musiał być skopiowany tyle razy, ile różnych typów stosów posiadamy. Wyobraź sobie teraz, że musisz mieć kilkanaście stosów przechowujących kilkanaście różnych rodzajów danych. Funkcja push i pop jest skopiowana kilkadziesiąt razy. Następnie zauważasz, że twój stos nie działa poprawnie. Musisz zatem poprawić kilkadziesiąt różnych wersji kodu. Jest to niezbyt zachęcająca perspektywa …
Jak zatem rozwiązać ten problem? Kłopot możemy załagodzić na kilka sposobów. Zajmiemy się tymi najlepszymi i najprostszymi metodami
Stos generyczny za pomocą unii
Otwórz ten artykuł i przeanalizuj stos w nim opisany. Zastanówmy się, jak możemy go zmodyfikować tak, aby przechowywać w nim różne rodzaje danych.
W naszym rozwiązaniu wykorzystamy unię. Unia jest podobnym tworem do struktury. Podobnie jak struktura, może zawierać kilka pól. Jednakże, w przeciwieństwie do niej, w unii wszystkie pola znajdują się pod tym samym adresem pamięci. Już ta definicja powinna ci nasuwać pomysł, w jaki wykorzystamy unię do stworzenia pseudo generyczności.
Utwórzmy sobie strukturkę person, która będzie jednym z możliwych typów danych, które będzie dało się odkładać na nasz nowy, lepszy stos.
1 2 3 4 5 | struct person { char name[32]; char surname[32]; }; |
Zadeklarujmy sobie naszą unię. Wewnątrz niej umieścimy wszystkie możliwe rodzaje danych, jakie będzie przechowywał nasz stos.
1 2 3 4 5 6 | union data_types { int number; char text[64]; struct person per; }; |
Dodajmy teraz pole naszej unii do struktury stack_node.
1 2 3 4 5 | struct stack_node { union data_types dt; struct stack_node* next; }; |
Musimy zastanowić się, jak możemy zmodyfikować funkcję push, aby poprawnie współpracowała z nową strukturą stack_node. Pójdziemy najprostszą możliwą ścieżką. Przekażemy unię jako argument funkcji. Zmodyfikowane funkcje push i pop widoczne są na listingach poniżej.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | struct stack_node *push(struct stack_node* top, union data_types new_dt) { struct stack_node* new_node = NULL; new_node = (struct stack_node*) malloc(sizeof(struct stack_node)); if(new_node!=NULL) { new_node->dt = new_dt; new_node->next = top; top = new_node; } return top; } bool pop(struct stack_node * * top, union data_types * result) { if ( * top != NULL) { *result = (*top)->dt; struct stack_node * tmp = (*top)->next; free(*top); *top = tmp; return true; } return false; } |
Jak powinieneś zauważyć, różnice nie są zbyt wielkie. Dotykają one definicji funkcji (w której jako argument przekazujemy teraz unię, a nie zmienną typu int). Więcej zmian zaszło w funkcji pop. Wcześniej funkcja ta zwracała wartość typu int. Teraz zwracamy bool. Dlaczego? Dzięki temu będziemy wiedzieli, kiedy stos jest pusty. Funkcja pop zwróci teraz w takim wypadku fałsz.
Spróbujmy teraz wykorzystać nasz stos.
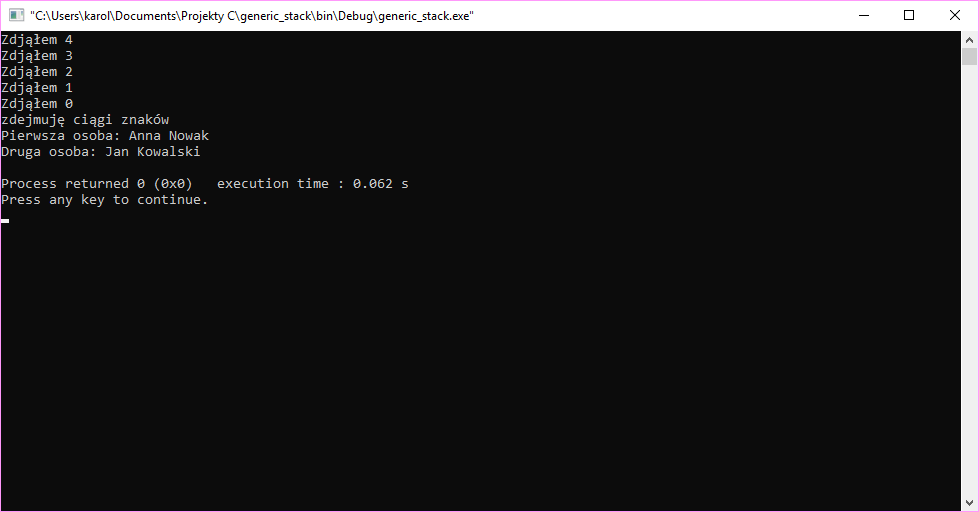
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | int main() { struct stack_node * stack1 = NULL, * stack2 = NULL; //Odkładamy na stos for (int i = 0; i<5; i++) { union data_types dt; dt.number = i; stack1 = push(stack1, dt); } union data_types person1, person2; strcpy(person1.per.name, "Jan"); strcpy(person1.per.surname, "Kowalski"); strcpy(person2.per.name, "Anna"); strcpy(person2.per.surname, "Nowak"); stack2 = push(stack2, person1); stack2 = push(stack2, person2); // Zdejmujemy ze stosu for (int i = 0; i<5; i++) { union data_types dt = pop( &stack1); printf("Zdjąłem %d\n", dt.number); } puts("zdejmuję ciągi znaków"); union data_types dt2, dt3; dt2 = pop( &stack2); dt3 = pop( &stack2); printf("Pierwsza osoba: %s %s\n", dt2.per.name, dt2.per.surname); printf("Druga osoba: %s %s\n", dt3.per.name, dt3.per.surname); } |
Powyżej znajduje się listing funkcji main. Co robimy naszym stosem? Na początku, w linii 2 tworzymy sobie dwa stosy. Pierwszy z nich wypełniamy liczbami naturalnymi od 0 do 4. Drugi z nich wypełniamy imionami i nazwiskami. W drugiej części funkcji zdejmujemy cyfry z pierwszego stosu i struktury z drugiego. Wynik działania funkcji wyświetlamy na ekranie.
Co można poprawić?
Zauważ, że w przypadku powyższej implementacji nie jesteśmy ograniczeni do przechowywania jednego konkretnego typu danych na danym stosie. Na jednym stosie możemy przechowywać kilka różnych rodzajów danych. Np.: Na szczycie może znajdować się liczba, niżej ciąg znaków, a na samym dnie osoba (struktura person). Dla rozróżnienia, co przechowujemy w danym polu stosu możemy dodać dodatkową zmienną typu enum, albo int w stack_node. Informowałaby nas, co przechowujemy w danym polu stosu. Modyfikację tego rodzaju zostawiam ci, czytelniku, na pracę domową.
Pełny kod programu, który omawialiśmy powyzej znajduje się w moim repozytorium.