Stos jest najprostszą dynamiczną strukturą danych. A w związku z tym będzie to także pierwsza dynamiczna struktura danych, którą poznasz.
Najpierw wyjaśnijmy, co to są te dynamiczne struktury danych?
Dynamiczna struktura danych – z czym to się je?
Zwykłą strukturą danych jest np.: na sztywno zadeklarowana tablica. Możesz w niej przechowywać różne dane. Ale – rozmiar zwykłej tablicy deklarowany jest na etapie kompilacji. W czasie działania programu nie możesz go zmienić.
Czasami takie rozwiązanie nam nie przeszkadza. Jeśli wiemy, na jakiej ilości danych będzie operował nasz program, po prostu przygotujemy go na najgorszą możliwą sytuację. Lecz takie podejście ma kilka wad. Przede wszystkim, strasznie marnujemy pamięć (obecnie i tak to nie ma znaczenia, ale my jesteśmy porządnymi programistami :-)). Po drugie, niektóre algorytmy ciężko przedstawić w formie zwykłej tablicy. Czasami potrzebujemy bardziej zaawansowanej struktury danych.
I tu z pomocą przychodzą dynamiczne struktury danych!
Oczywiście, będzie się z tym wiązała zabawa z najukochańszymi wskaźnikami. Co byśmy bez nich poczęli? No dobra, zaczynamy.

Stos – podstawowe informacje
Stos działa na bardzo prostej zasadzie. Wyobraźmy sobie, że posiadamy kilka talerzy. Nasz stół, na którym będziemy je układali, będzie naszą pamięcią. Zasada dotycząca stosu jest prosta. Jedyne operacje, jakie możemy na nim wykonywać, dotyczą szczytu stosu. Jeśli nasz stos jest pusty, możemy wykonać tylko jedną rzecz – położyć talerz na stole. Do talerza możemy włożyć jakąś karteczkę z zapisaną liczbą.
Hurra! Nasz stos ma już jeden element! W tym momencie możemy wykonać już trzy operacje. Możemy zobaczyć, co znajduje się na kartce znajdującej się na tym talerzu (funkcja peek). Możemy do stosu dołożyć kolejny talerz (funkcja push). Ostatecznie możemy skończyć tę zabawę i zabrać znajdujący się na stole talerz.
Mimo odłożenia na stos kilku talerzy, zasada dostępu jedynie do szczytowego elementu dalej obowiązuje. Nie możemy wyjąć talerza znajdującego się w środku tego stosu ani zobaczyć, co się w nim znajduje, bo cała nasza minsterna konstrukcja się wtedy rozleci. Wyobraźmy sobie ponadto, że nasza ręka dotykająca talerza jest swego rodzaju wskaźnikiem. Może ona dotknąć tylko talerza znajdującego się na szczycie. Jeśli jednak ręka nie będzie wiedziała, gdzie znajduje się stos talerzy, to nie będzie można nim zarządzać. Pamiętaj więc, aby nigdy nie zgubić wskaźnika do wierzchołka stosu. Jest to błąd, za który możesz srogo zapłacić.
Tyle teorii. Pora na praktykę.
Stos – definicja struktury przechowującej dane
Struktura przechowująca dane naszego stosu będzie bardzo prosta. Nie masz się czego bać. Zresztą i tak omówimy ją krok po kroku. Spójrz na poniższy listing:
1 2 3 4 5 | struct stack_node { int data; struct stack_node* next; }; |
Zwyczajna struktura, co nie? W trzeciej linijce utworzyliśmy sobie zwyczajną zmienną typu integer o nazwie data. Na podstawie tego możesz domyślić się, że nasz stos będzie przechowywał liczby. Oczywiście, stos może przechowywać dowolne typy danych. Ale dla uproszczenia przyjmijmy, że będą to właśnie liczby całkowite.
Tajemnie wygląda czwarta linijka. Jest to wskaźnik na strukturę typu, którą właśnie tworzymy o nazwie next? Co to jest? Wygląda, jak niby-rekurencja. W istocie, można to tak potraktować. Wskaźnik next przechowuje adres elementu, który znajduje się o jeden stopień „niźej” w tej strukturze. Jeśli omawiamy element znajdujący się na samym dnie, to wskaźnik next będzie miał wartość NULL. Jak sobie to wyobrazić w rzeczywistości? Talerz znajdujący się na szczycie, dotyka swoją powierzchnią talerza znajdującego się pod spodem. I to talerz i to talerz, a więc mieści się to w definicji struktury stack_node. Ten „dotyk” możemy wyobrazić sobie jako wskaźnik next. Talerz znajdujący się na samym dnie stosu dotyka stołu. Stół nie jest talerzem a więc wskaźnik ten przyjmie wartość NULL.
Dzięki temu, że wskaźnik next może być NULL-em możemy bardzo łatwo rozpoznać ostatni element stosu. Tylko egzemplarz struktury znajdujący się na dnie stosu będzie miał w polu next wartość NULL.
Stos – funkcje push, pop, peek
Stos – push
1 2 3 4 5 6 7 8 9 10 11 12 | struct stack_node *push(struct stack_node* top, int number) { struct stack_node* new_node = NULL; new_node = (struct stack_node*) malloc(sizeof(struct stack_node)); if(new_node!=NULL) { new_node->data = number; new_node->next = top; top = new_node; } return top; } |
Pierwsza z funkcji, które omówimy dodaje na szczyt stosu kolejny element. Jest ona prosta, jak wszystko w informatyce 🙂 Niemniej, omówimy ją linijka po linijce (no, prawie – oczywiste rzeczy pominiemy 🙂
Najpierw przeanalizujmy definicję naszej funkcji. Zwraca ona element typu wskaźnik na stack_node. Jako argumenty przyjmujemy wskaźnik na szczyt stosu oraz wartość liczbową, jaką zapiszemy w nowym elemencie.
W trzeciej linijce tworzymy sobie wskaźnik na stack_node. stack_node, jak pamiętamy, przechowuje pojedynczy element (talerz) naszego stosu. Na początku temu wskaźnikowi przypisujemy wartość NULL. Oznacza to, że ten element tak właściwie nie istnieje. Dzieje się tak, gdyż dopiero go tworzymy.
W linijce czwartej dzieją się prawdziwe cuda. Przydzielamy pamięć dla naszego nowo_utworzonego wskaźnika new_node. To co znajduje się tuż po znaku =, w nawiasach, to rzutowanie. Mówimy kompilatorowi, że pamięć, którą właśnie przydzielił to jest pamięć dla elementu typu stack_node. Oczywiście, kompilator może się domyślić takiej oczywistości, ale nie radził bym na tym polegać. Po rzutowaniu znajduje się standardowe wywołanie funkcji malloc. W nawiasie podaliśmy, ile bajtów musimy zarezerwować. Nie znamy rozmiaru naszej struktury, ale zna ją operator sizeof, z którego w tym momencie skrzętnie korzystamy.
Piąta linijka nie powinna być trudna do rozszyfrowania. Sprawdzamy, system operacyjny przydzielił pamięć dla nowego elementu naszego stosu. Jeśli tak się stało, wykonujemy zawartość naszego warunku. Jeśli nie – właściwie kończymy funkcję.
W siódmej linijce do nowo utworzonego elementu stosu zapisujemy informację, którą chcemy przechowywać. Znacznie ciekawsza jest ósma dziewiąta linijka. Co robimy w ósmej? Do pola next nowo utworzonego elementu zapisujemy wskaźnik na aktualny wierzchołek stosu. Dlaczego tak się dzieje? Analogicznie do stosu talerzy. Jeśli na naszym stosie znajdują się trzy talerze, to wskaźnik top będzie wskazywał na ten trzeci, znajdujący się na samym szczycie. Jeśli w tym momencie dołożymy czwarty talerz, to wskaźnik top musi wskazywać na nowo dołożony talerz. Natomiast ten dodany talerz musi wiedzieć, że pod nim znajduje się „były” wierzchołek stosu, czyli top.
W dziewiątej linijce robimy to, co powyżej opisałem. Zastępujemy wartość aktualnego szczytu stosu nowym elementem.
W 11 linijce zwracamy nowy wierzchołek stosu. Możesz zadać pytanie, po co, skoro do funkcji przekazujemy top jako wskaźnik, który modyfikujemy w linijce dziewiątej? Pozostawiam te przemyślenia jako pracę domową. Wyjaśnię to w jednym z przyszłych artykułów (jeśli go stworzę, w tym miejscu pojawi się link do niego).
Stos – pop
Skoro umieścimy jakieś elementy na stosie, to musimy umieć również je zdjąć. Nie ma co ukrywać, funkcja pop jest nieco bardziej skomplikowana. Ale tylko troszeczkę, nie masz się czym przejmować xD
1 2 3 4 5 6 7 8 9 10 11 12 | int pop(struct stack_node **top) { int result = -1; if(*top!=NULL) { result = (*top)->data; struct stack_node *tmp = (*top)->next; free(*top); *top = tmp; } return result; } |
Nie taki diabeł straszny, jak go malują. Poradzimy sobie z omówieniem tej funkcji.
Najpierw, standardowo, definicja. Funkcja zwraca wartość typu int. Jako argument przyjmujemy podwójny (COO?) wskaźnik na wierzchołek stosu.
Dlaczego podwójny? Abyśmy go mogli zmodyfikować wewnątrz funkcji. Więcej szczegółów na ten temat niebawem.
W trzeciej linijce tworzymy sobie nową zmienną int. W niej będziemy przechowywali wynik działania naszej funkcji. Domyślnie będziemy zwracali -1. Zakładamy więc, że w naszym stosie będziemy przechowywali tylko i wyłącznie liczby nieujemne.
Czwarta linijka stanowi zabezpieczenie przed tym, abyśmy przypadkiem nie próbowali usuwać elementu z pustego stosu. Wierzchołek pustego stosu będzie po prostu NULL-em, którego wyłapie ten warunek. W przeciwnym wypadku, gdy na stosie znajdują się jakieś elementy, musimy nieco bardziej się natrudzić.
W szóstej linijce pobieramy zawartość aktualnego wierzchołka stosu do zmiennej result. Musimy pamiętać o dodatkowej gwiazdce i nawiasach. Jako argument przyjęliśmy podwójny wskaźnik na zmienną wierzchołka stosu. Strzałka wykonuje nam tak jakby jedynie jedną dereferencję, a my musimy wykonać aż dwie. Właśnie dlatego musimy zastosować taki dziwny zapis.
W siódmej linijce tworzymy sobie wskaźnik na strukturę stack_node o nazwie tmp i zapisujemy do niego wskaźnik na element stosu znajdujący się poniżej top. Dlaczego? To proste – musimy wiedzieć, jaki będzie nasz następny wierzchołek, po usunięciu aktualnego elementu znajdującego się na szczycie.
A co, jeśli usuwamy właśnie ostatni element? Wtedy we wskaźniku next->; będzie znajdował się NULL. Jeśli ten NULL przypiszemy do wskaźnika na wierzchołek stosu (co czynimy w linijce dziewiątej) to jednoznacznie poinformujemy programistę korzystającego z naszego stosu że jest on pusty.
W ósmej linijce zwalniamy pamięć. Porządny programista powinien po sobie sprzątać i właśnie to w tym miejscu robimy.
O dziewiątej linijce wspominałem już wcześniej. Zapisujemy w niej wskaźnik na nowy wierzchołek stosu. Zmiana ta będzie widoczna na zewnątrz funkcji.
Linijka 11 to tylko formalność. Zwracamy wartość zmiennej result, czyli to, co znajdowało się w aktualnym elemencie stosu.
Stos – peek
Została nam do wykonania ostatnia funkcja. Co będzie robiło peek? To samo co pop, ale bez zdejmowania znajdującego się na szczycie elementu ze stosu. Po prostu, czasem istnieje potrzeba przeczytania zawartości tego, co znajduje się na szczycie bez zdejmowania tego. Np.: Chcemy zobaczyć, jak brudny jest talerz po wczorajszym obiedzie, ale nie chce nam się w chwili obecnej tego zmywać 🙂 Bez funkcji peek byłoby to niemożliwe xD
1 2 3 4 5 | int peek(struct stack_node *top) { if(top!=NULL) return top->data; else return -1; } |
Chyba już wiesz, że jest to funkcja najprostsza z całej trójki 🙂 Mimo wszystko, omówimy ją, choć nie powinieneś mieć problemu z samodzielną interpretacją.
Definicja – zwracamy liczbę typu int, czyli to, co znajduje się na szczycie stosu. Jako argument przyjmujemy pojedynczy wskaźnik na strukturę stack_node przechowującą wierzchołek naszego stosu.
W trzeciej linijce sprawdzamy, czy nasz stos przypadkiem nie jest pusty. Jeśli nie jest, to zwracamy zawartość pola data tego, co znajduje się na szczycie. W przeciwnym wypadku zwracamy -1 (wcześniej przyjęliśmy, że oznacza to albo błąd, albo pustotę naszego stosu).
No i to prawie wszystko. Zostało pokazać ci, mój drogi czytelniku, jak używać stworzonego przed chwilą stosu.
Funkcja main – czyli jak używać stworzonego stosu?
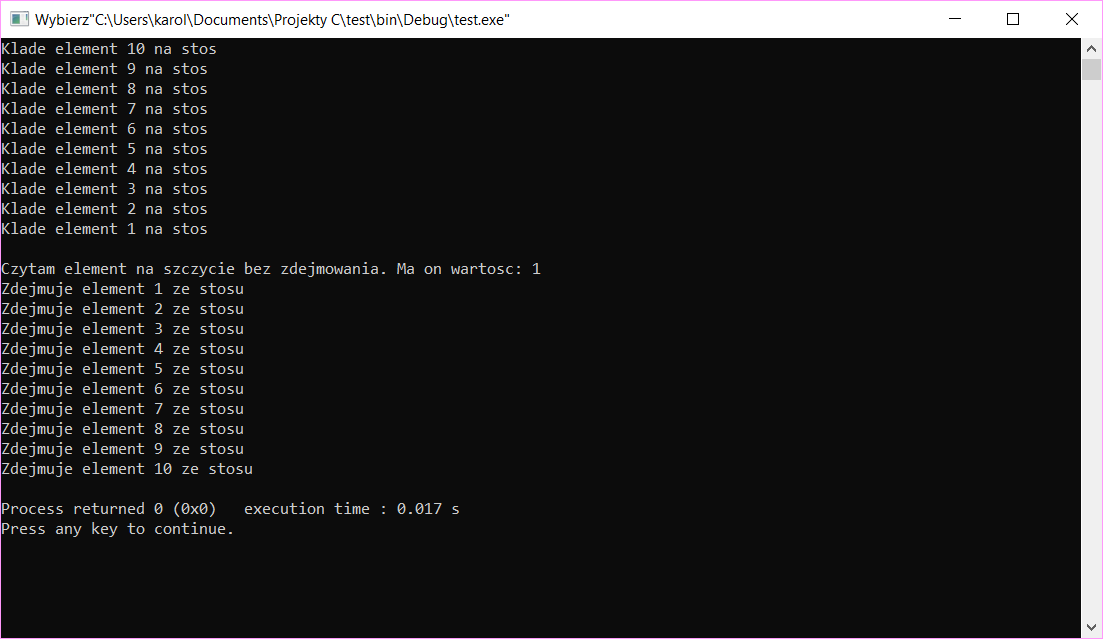
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | int main() { struct stack_node* our_stack = NULL; for(int i = 10;i>0;i--) { our_stack = push(our_stack,i); printf("Klade element %d na stos\n",i); } printf("\nCzytam element na szczycie bez zdejmowania. Ma on wartosc: %d\n",peek(our_stack)); while(our_stack!=NULL) { printf("Zdejmuje element %d ze stosu\n",pop(&our_stack)); } return 0; } |
Co robimy? W trzeciej linijce tworzymy sobie wskaźnik na wierzchołek stosu. Przypisujemy mu wartość NULL co oznacza, że stos jest pusty. (Pamiętaj – zawsze przypisuj wskaźnikowi na wierzchołek pustego stosu wartość NULL – inaczej cała ta konstrukcja nie będzie prawidłowo działać) .
W czwartej linijce znajduje się pętla for, wewnątrz której dodajemy dziesięć elementów na stos w porządku malejącym. W szóstej linijce dodajemy element na szczyt naszego stosu. W siódmej wypisujemy sobie, jaki element właśnie dodaliśmy.
W linijce dziewiątej robimy użytek z funkcji peek. Odczytujemy, co przechowuje element na szczycie stosu bez zdejmowania go.
W dziesiątej linijce znajduje się pętla while. Robimy użytek z tego, że NULL wskazuje na koniec stosu. Przeszukujemy stos do momentu, w którym wierzchołek nie będzie wskazywał na NULL. W linijce dwunastej zdejmujemy element ze szczytu stosu. Wypisujemy także jego wartość.
To tyle. Mam nadzieję, że wszystko zrozumiałeś 🙂 Jeśli masz jakieś pytania, pisz w prywatnej wiadomości na Fanpage’u lub na adres email podany na samej górze. Możesz także napisać komentarz.
Jeśli ci się podobało, pamiętaj o polubieniu mojego Fanpage’a. Dzięki temu będziesz na bieżąco z nowymi artykułami. A ja będę szczęśliwy mając kolejnego stałego czytelnika 🙂
Kod wyżej omawianego programu znajduje się w moim repozytorium.